AIOps automation with Ansible - Solution Guide

Overview
Traditional event-driven automation is deterministic – for every event you want to handle, you write a specific rule and a corresponding action. Ten known failure scenarios means ten rules. A hundred means a hundred. This creates a linear scaling problem: as your IT environment grows in complexity, so does the number of rules you must author, test, and maintain.
| Approach | Events | Rules Required | Actions |
|---|---|---|---|
| Traditional EDA | 10 | 10 | 10 |
| Traditional EDA | 100 | 100 | 100 |
| Traditional EDA | 1,000 | 1,000 | 1,000 |
| AIOps with EDA | 1,000 | 1 (+ AI inference) | Dynamic |
AIOps breaks this linear relationship by inserting AI inference between the event and the action. Instead of hand-coding a rule for every possible failure mode, a single intelligent workflow captures the event, uses AI to diagnose the root cause, and generates the remediation dynamically. This guide demonstrates how to build that workflow using Ansible Automation Platform.
Where does AIOps fit?
The industry is moving through three generations of IT automation: task-based automation (running known playbooks on a schedule or trigger), event-driven automation (reacting to known conditions with pre-written rules), and agent-driven automation (handling novel situations with real-time contextual judgment). Most organizations today rely heavily on task-based automation, with event-driven adoption growing and agent-driven still emerging. AIOps with Ansible bridges event-driven and agent-driven by using AI to handle situations you didn’t explicitly write rules for, without requiring a fully autonomous agent.
- Overview
- Background
- Solution
- Prerequisites
- AIOps Workflow
- 1. Event-Driven Ansible (EDA) Response
- 2. Log Enrichment and Prompt Generation Workflow
- 3. Remediation Workflow
- 4. Execute Remediation
- Validation
- AIOps Maturity Path
- Related Guides
- Summary
Background
AIOps stands for artificial intelligence for IT operations. It refers both to a modern approach to managing IT operations and to the software systems that implement it. AIOps uses data science, big data, and machine learning to augment–or even automate–many traditionally manual IT tasks. The goal is to improve issue detection, root cause analysis, and system resolution.
There are three major parts of AIOps:
 Observability
Observability Inference
Inference Automation
Automation

- Observability: Understanding the internal state of a system through logs, metrics, and traces.
- Inference: Using AI models to make predictions based on new data.
- Automation: Automatically detect, respond to, and resolve IT issues.
Ansible Automation Platform connects observability and inference to build self-healing infrastructure.
AIOps adoption can be incremental.
You don’t need full automation on Day One. Start small, think big!
Solution
What makes up the solution?
- Red Hat AI for understanding service issues [Link]
 Automation code assistant to generate remediation playbooks [Link]
Automation code assistant to generate remediation playbooks [Link]- Red Hat Lightspeed for CVE and Advisor remediation playbooks [Link]
 Ansible Automation Platform (AAP) workflows for orchestration [Link]
Ansible Automation Platform (AAP) workflows for orchestration [Link] Event-Driven Ansible (EDA) to listen to real-time service events [Link]
Event-Driven Ansible (EDA) to listen to real-time service events [Link]
EDA is part of Ansible Automation Platform.
It is referred to separately sometimes depending on the workflow. EDA uses rulebooks to monitor events, then executes specified job templates or workflows based on the event. Think of it simply as inputs and outputs. EDA is an automatic way for inputs into Ansible Automation Platform, where Ansible Automation Platform is the output (running a job template or workflow).
Terminology update – Lightspeed rebranding.
Red Hat has consolidated its AI-powered services under the Lightspeed brand. Ansible Lightspeed Code Assistant is now Automation code assistant (supports Gemini, Red Hat AI, or IBM watsonx). Ansible Lightspeed Intelligent Assistant is now Automation intelligent assistant. Red Hat Insights (console.redhat.com) is now Red Hat Lightspeed. The functionality is the same – only the branding has changed. This guide uses both old and new names where they appear in existing code and screenshots.
Who Benefits
| Persona | Challenge | What They Gain |
|---|---|---|
| Manually triaging alerts, running the same diagnostic steps repeatedly, and writing one-off remediation scripts | Automated incident detection, AI-generated diagnosis, and dynamically generated playbooks – less toil, faster recovery | |
| Designing event-driven workflows that scale beyond what deterministic rules can cover | A reference architecture for bridging EDA, AI inference, and playbook generation – adaptable to any observability tool or ITSM | |
| Justifying AI investment and managing operational risk while reducing MTTR | Incremental adoption path (Crawl → Walk → Run), measurable reduction in manual intervention, and governance guardrails before full automation |
Prerequisites
Ansible Automation Platform
- Ansible Automation Platform 2.5+ – Required for enterprise Event-Driven Ansible support.
Featured Ansible Content Collections
| Collection | Type | Purpose |
|---|---|---|
| ansible.eda | Certified | EDA event sources and filters (Kafka, webhooks, etc.) |
| ansible.controller | Certified | AAP configuration as code (job templates, workflows, surveys) |
| ansible.scm | Certified | Git operations (commit and push generated playbooks) |
| infra.ai | Validated | Provisions RHEL AI infrastructure (AWS, Azure, GCP, bare metal) |
| redhat.ai | Certified | Configures and serves AI models using InstructLab |
Need to deploy your own AI inference endpoint?
The
infra.aiandredhat.aicollections automate the full stack – from provisioning a GPU instance to serving a model. See the companion guide AI Infrastructure automation with Ansible for a complete walkthrough.
External Systems
| System | Required | Examples |
|---|---|---|
| Observability tool | Yes | Filebeat, IBM Instana, Splunk, Dynatrace, Prometheus |
| Message queue | Optional (depends on observability tool) | Apache Kafka, AWS SQS, Azure Service Bus |
| AI inference endpoint | Yes | Red Hat AI (RHEL AI + InstructLab) or any OpenAI-compatible API |
| Automation code assistant | Yes | Automation code assistant (formerly Ansible Lightspeed) with Gemini, Red Hat AI, or IBM watsonx |
| Red Hat Lightspeed | Recommended | CVE and Advisor remediation playbooks via console.redhat.com (formerly Red Hat Insights) |
| Git repository | Yes | GitHub, GitLab, Gitea |
| Chat or ITSM tool | Recommended | Mattermost, Slack, ServiceNow |
AIOps Workflow
An AIOps workflow has four (4) parts:
-
Event-Driven Ansible (EDA) Response
Respond to an event, such as a systemd application outage. This falls under the Observability part of the AIOps workflow. EDA allows us to plug-in observability to an automation workflow.
-
Log Enrichment and Prompt Generation Workflow
AAP coordinates with Red Hat AI, notifies your chat application or ITSM (IT service management tool). This falls under the Inference part of the AIOps workflow. Again, Ansible Automation Platform ties this into an automation workflow.
-
Remediation Workflow
Generates a playbook via Ansible Lightspeed, syncs it to Git, builds another Job Template. This also falls under the Inference part of the AIOps workflow. For this solution we are using one AI LLM endpoint (Red Hat AI) to figure out what the issue is and diagnose it, and one AI LLM endpoint to create an Ansible Playbook to remediate the issue. This is considered a multi-LLM workflow, as we are using 2 or more LLM endpoints within our workflow.
-
Execute Remediation
The final Job Template that fixes the issue on your IT infrastructure. This is executing the Ansible Playbook that was generated in the previous workflow. This falls under the automation part of AIOps and wraps up our self healing infrastructure use-case.
Operational Impact per Stage
| Stage | Operational Impact | Why |
|---|---|---|
| 1. EDA Response | None | Read-only – EDA listens to events and triggers a workflow. No changes to systems. |
| 2. Enrichment Workflow | Low | Collects logs, calls an AI API, posts to chat/ITSM. The only write is a notification message – no infrastructure changes. |
| 3. Remediation Workflow | Low | Generates a playbook, commits to Git, creates a Job Template. Prepares the fix but does not touch production infrastructure. |
| 4. Execute Remediation | High | Modifies production infrastructure (restarting services, changing config files, etc.). Should go through a change window or approval gate. |
Stages 1-3 are safe to experiment with in any environment. Stage 4 is where production risk lives – which is why the guide recommends a manual approval gate at the Walk maturity level and policy-governed auto-approval at the Run level.
Could this be one workflow?
Yes – but it’s broken up for review points and easier adoption.
Example Workflow Diagram
This is a workflow example from our hands-on workshop Introduction to AI-Driven Ansible Automation

This is a high level diagram.
It shows an opinionated approach for AIOps that is easily customizable for a variety of IT infrastructure use-cases.
1. Event-Driven Ansible (EDA) Response
The first part of the AIOps workflow is the Event-Driven Ansible (EDA) Response. Here is a breakdown of the four main components:

- IT infrastructure event
- Observability tool picks up event
- EDA sees event in message queue
- Execute Enrichment workflow
Example Walkthrough for EDA Response
In our hands-on workshop we simulate an httpd application outage. This is how the workflow works:
- IT infrastructure event: The student will break httpd using a Job Template
- Observability tool picks up event: Filebeat monitors Apache logs, Kafka acts as the event transport
- EDA sees event in message queue: EDA listens to Kafka, launches automation workflows
- Execute Enrichment workflow Ansible Automation Platform kicks off part 2, Log Enrichment and Prompt Generation Workflow
Why Kafka?
Apache Kafka is a distributed streaming platform used for building real-time data pipelines and streaming applications, enabling applications to publish, consume, and process high volumes of data streams. It is all open source and self hosted and works great for workshops. This could be replaced by any event bus of your choosing. Event-Driven Ansible has numerous plugins including integrations with AWS SQS, AWS CloudTrail, Azure Service Bus, and Prometheus.
Why Filebeat?
Filebeat is a lightweight shipper for logs. It is also free and open source and works great for lab environments. Event-Driven Ansible has numerous plugins including integrations with BigPanda, Dynatrace, IBM Instana, Zabbix, and CyberArk.
Do you need both a message bus and an observability tool?
It depends on the particular integration. Generally combining a message bus and an observability tool will scale the most, but it really depends on your particular use-case, amount of events, etc. Many observability platforms can work directly with Event-Driven Ansible just fine.
Now that you understand our workflow example, lets dive into production-grade examples:
1. IT infrastructure event:
What kind of events are relevant in an AIOps workflow? EDA’s value proposition is that it is extremely versatile and pluggable. This means that Ansible Automation Platform can effectively handle any type of event.
However here is a great list of ideas:
 Application-Level Events
Application-Level Events
| Event | Source | Example Response |
|---|---|---|
| application service crash or stopped | systemd, monit, or Prometheus alert |
Restart, notify on Slack, check last logs via journald |
| High 5xx error rate in NGINX/Apache | Web server logs, Prometheus metrics | Trigger Ansible to roll back a recent deployment or redirect traffic |
| Application log shows exception spike | Log aggregator (ELK, Loki, Datadog) | Run Ansible remediation that restarts service and clears cache |
| Web app fails readiness check | Kubernetes liveness/readiness probe | Reboot pod, scale another replica, or notify developer team |
| API latency exceeds threshold | APM tool (e.g., Dynatrace, Instana) | Provision more backend instances or restart slow services |
 Infrastructure & Platform Events
Infrastructure & Platform Events
| Event | Source | Example Response |
|---|---|---|
| Disk space usage > 90% | Prometheus Node Exporter, Zabbix | Clean temp files, archive logs, or extend volume |
| High CPU load on EC2 or VM | CloudWatch, Telegraf, etc. | Scale out VM set or move workloads |
| OOM Kill in container | Kubernetes Events | Restart pod, notify engineering, increase memory limits |
| Node goes NotReady in Kubernetes | K8s API | Cordon node, reassign pods, and open a ticket |
| Filesystem becomes read-only | dmesg, audit logs, OS-level alerts |
Unmount and remount or migrate app to another host |
 Network & Security Events
Network & Security Events
| Event | Source | Example Response |
|---|---|---|
| Interface down / Link failure | SNMP traps, syslog | Notify NOC, run Ansible playbook to reroute traffic |
| Unauthorized SSH attempt detected | Fail2Ban, syslog, SIEM | Block IP, rotate SSH keys, notify SOC |
| SSL certificate expiring soon | Certbot, monitoring tool | Auto-renew with Let’s Encrypt, push new cert with Ansible |
| DNS resolution failures | systemd-resolved, DNS logs |
Switch DNS provider or fix /etc/resolv.conf |
 Observability-Driven Triggers
Observability-Driven Triggers
| Event | Source | Example Response |
|---|---|---|
| SLO breach warning (latency or error rate) | SRE observability tool | Pre-emptively scale or rollback new features |
| New critical error introduced in logs post-deploy | ELK, Honeycomb, etc. | Rollback deployment via Ansible |
| User reports spike via feedback or ticket | ITSM tools | Use AI to correlate symptoms, gather diagnostics, and kick off a fix |
2. Observability tool picks up event:
Now that you have a great understanding of types of events, what are great examples of observability tools that can plug-in to an AIOps workflow:
Filebeat
![]()
Filebeat is a lightweight, open-source log shipper from Elastic that forwards logs from end-systems to a message aggregator. It is not an observability platform on its own – it requires a message bus like Kafka to transport events to EDA. We use it in the AIOps workshop because it is free, low-overhead, and easy to deploy in lab environments.
IBM Instana

IBM Instana provides real-time observability across hybrid and multicloud environments with automatic change detection, end-to-end tracing, and context-rich alerts. Its built-in anomaly detection and contextual correlation make it a natural event source for EDA rulebooks – Instana can trigger automation workflows directly or through a message bus like Kafka.
Splunk
![]()
Splunk ingests logs, metrics, traces, and events from virtually any source, providing a centralized view of system health across complex IT environments. Its machine learning and anomaly detection capabilities can proactively surface issues, making it an ideal trigger source for EDA-driven remediation workflows.
3. EDA sees event in message queue
Message queues are optional depending on the observability tool. For example IBM Instana can work directly with Event-Driven Ansible to trigger automation jobs, or it can work with a message queue like Apache Kafka. Here are some examples of other message queues that Ansible Automation Platform works with:
AWS SQS
![]()
Amazon SQS (Simple Queue Service) is a managed message queuing service that decouples event producers from consumers. In an AIOps workflow, observability tools or AWS CloudWatch can publish events to an SQS queue, and EDA subscribes to that queue to trigger automation.
Azure Service Bus

Azure Service Bus on Automation hub
Azure Service Bus is a fully managed enterprise messaging service with message queuing and publish-subscribe capabilities. EDA can subscribe to Service Bus topics or queues to detect events from Azure resources and third-party systems, making it a natural fit for cloud-centric AIOps workflows.
Kafka
![]()
Apache Kafka is a high-throughput, fault-tolerant event streaming platform that collects telemetry data, logs, alerts, and state changes from diverse sources. EDA listens to Kafka topics for specific patterns and triggers remediation workflows. Kafka’s ability to decouple producers and consumers makes it ideal for scaling AIOps pipelines across large environments.
Example rulebook for Kafka:
---
- name: Web app issue
hosts: all
sources:
- ansible.eda.kafka:
host: service1
port: 9092
topic: httpd-error-logs
rules:
- name: apache shutdown detected
condition: event.body.message is search("shutting down")
action:
run_workflow_template:
organization: "Default"
name: "{{ workflow_template_name | default('AI Insights and Lightspeed prompt generation') }}"
- name: show event messages
condition: event.body.message is defined
action:
debug:
msg: "{{ event.body.message }}"
2. Log Enrichment and Prompt Generation Workflow
The second part of the AIOps workflow is the Log Enrichment and Prompt Generation Workflow (or for shorthand the Enrichment Workflow). Here is a breakdown of the four main components:
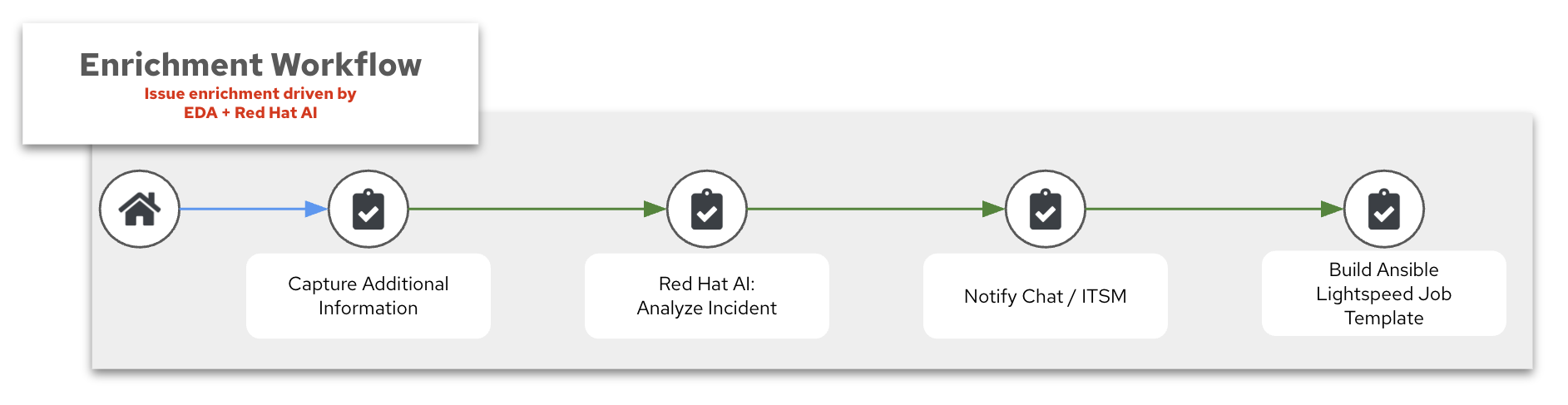
- Capture Additional Information
- Red Hat AI: Analyze Incident
- Notify Chat / ITSM
- Build Ansible Lightspeed Job Template
1. Capture Additional Information
In our AIops workshop we have an Ansible Playbook that captures additional information from the host. If server01 reports an outage with an application (e.g. httpd), we can have Ansible collect additional information to
- Confirm the systemd process is down
- Collect relevant logs
- Collect system information (operating system, memory, etc).
This process is similar to agentic workflow, where we capture information, just as we need it.
What is an agentic workflow?
An agentic workflow with AI refers to a system where an AI agent is empowered to make decisions, take actions, and pursue goals across multiple steps–often autonomously. Unlike a single API call or a static prompt, agentic workflows involve planning, reasoning, tool use, and possibly interacting with other agents or services. These agents maintain state, adjust behavior based on feedback, and operate in loops (like ReAct or AutoGPT). The goal is to replicate more human-like problem solving, where the AI isn’t just responding, but actively working through a task. This is especially useful in AIOps, automation, and multi-step orchestration.
In this case we have a static workflow versus a fully agentic workflow, but unlike just a static LLM query, we are giving inputs from multiple sources, the event, the observability tool, system logs, and an Ansible Playbook running on the host to retrieve any additional info. In the future you will see increasingly more and more ability for the operations team to allow AI tools the ability to act more autonomously.
2. Red Hat AI: Analyze Incident
To interface with Red Hat AI we can use the redhat.ai content collection, which wraps the OpenAI-compatible API into native Ansible modules. Many AI tools, including Red Hat AI, are using the OpenAI API standard.
Why is the OpenAI API the standard?
The OpenAI API (
/v1/completions,/v1/chat/completions) became a standard for interacting with LLMs because:
- It was the first widely adopted commercial LLM API
- It has a clean, JSON-based format that is easy to integrate
- Tons of apps, SDKs, frameworks (like LangChain, AutoGen, Semantic Kernel) built around it
In an AIOps context, inference refers to the process where an AI model receives a question or input–such as a system error, log snippet, or performance metric–via an API, and returns a prediction or insight. This could include identifying root causes, classifying incidents, or suggesting remediation steps. The model has already been trained, so inference is the real-time application of that knowledge to live operational data. It’s a key part of integrating AI into IT workflows, enabling automated, intelligent responses without human intervention.
Here is an Ansible task for inference to Red Hat AI using the redhat.ai collection:
- name: Analyze incident with Red Hat AI
redhat.ai.completion:
base_url: "http://{{ rhelai_server }}:{{ rhelai_port }}"
token: "{{ rhelai_token }}"
prompt: "{{ gpt_prompt | default('What is the capital of the USA?') }}"
model_path: "/root/.cache/instructlab/models/granite-8b-lab-v1"
delegate_to: localhost
register: gpt_response
base_url:The URL of the Red Hat AI server (the module appends/v1/completionsautomatically).token:Authentication token for the AI server.prompt:The text input or question you want the AI to respond to.model_path:The path to the specific AI model used to generate the response.
The response is available as gpt_response.choice_0_text (the first answer) and gpt_response.raw_response (the full JSON payload).
For advanced use cases that need full control over parameters like temperature, max_tokens, top_p, and n, use the raw_input parameter instead:
- name: Analyze incident with Red Hat AI (advanced)
redhat.ai.completion:
base_url: "http://{{ rhelai_server }}:{{ rhelai_port }}"
token: "{{ rhelai_token }}"
raw_input:
prompt: "{{ gpt_prompt }}"
model: "/root/.cache/instructlab/models/granite-8b-lab-v1"
max_tokens: 50
temperature: 0
top_p: 1
n: 1
delegate_to: localhost
register: gpt_response
temperature:Controls randomness; lower values make outputs more deterministic, while higher values increase creativity.max_tokens:The maximum number of tokens (words or sub-words) the AI can generate in its response.top_p:Limits the AI to sampling from the top probability mass (e.g., top 90%) for more focused outputs.n:Specifies how many different completions you want the AI to generate for the given prompt.
Alternatively, you can call the OpenAI-compatible API directly with ansible.builtin.uri. This approach works with any model server – not just Red Hat AI:
- name: Send POST request using uri module
ansible.builtin.uri:
url: "http://{{ rhelai_server }}:{{ rhelai_port }}/v1/completions"
method: POST
headers:
accept: "application/json"
Content-Type: "application/json"
Authorization: "Bearer {{ rhelai_token }}"
body:
prompt: "{{ gpt_prompt | default('What is the capital of the USA?') }}"
max_tokens: "{{ max_tokens | default('50') }}"
model: "/root/.cache/instructlab/models/granite-8b-lab-v1"
temperature: "{{ input_temperature | default(0) }}"
top_p: "{{ input_top_p | default(1) }}"
n: "{{ input_n | default(1) }}"
body_format: json
return_content: true
status_code: 200
timeout: 60
register: gpt_response
Both approaches produce the same result – the redhat.ai.completion module handles the HTTP details (headers, URL path, body format) for you, while ansible.builtin.uri gives you full control over the raw request.
Why set n: 1?
You’d want
n: 1when you’re only interested in getting a single best response from the AI:
- Reduces overhead: Less processing time and memory usage, especially important when running local models like Red Hat AI.
- Simplifies parsing: You don’t have to iterate over multiple completions or choose the best one.
- Keeps things deterministic (especially with
temperature: 0): When you’re aiming for predictable, repeatable automation, one clear response is ideal.n: 1is perfect for most automation tasks where you just need one solid, confident answer without extra noise.
Tools That Support the OpenAI-Compatible API
| Tool | Description |
|---|---|
| vLLM | Efficient LLM serving engine with OpenAI-compatible endpoints for both completion and chat APIs |
| llama.cpp | Lightweight C++ LLM inference with a --server mode that mimics OpenAI API |
| Ollama | CLI + local model manager that serves LLaMA and Mistral models via OpenAI-compatible endpoints |
| LM Studio | GUI for local LLMs that exposes an OpenAI-compatible endpoint |
| Text Generation WebUI | Hugely flexible GUI for multiple models (GGUF, HF, etc), includes OpenAI API adapter |
| LocalAI | Drop-in OpenAI replacement server with multi-backend support (llama.cpp, GPT4All, etc) |
| DeepInfra | Model hosting provider offering OpenAI-compatible APIs |
| Replicate | Platform for hosting ML models with optional OpenAI-style API access |
| Anyscale | Provides OpenAI-compatible APIs for hosted open models with high performance |
3. Notify Chat / ITSM
This is where we synchronize the output from Red Hat AI to another outside system. Here some great options:
Mattermost
![]()
Mattermost is an open-source, self-hostable chat platform with robust API and webhook integrations. We use it in the AIOps workshop as a free alternative to Slack or Microsoft Teams – Ansible posts AI-generated diagnoses and remediation updates to a Mattermost channel in real time.
ServiceNow
![]()
ServiceNow is an enterprise-grade IT Service Management (ITSM) platform and the system of record for incidents, changes, and problem management. In AIOps workflows, AI-driven insights enrich ServiceNow tickets automatically, and Ansible closes the loop by triggering remediation directly from ticket data.
Slack
![]()
Slack is an enterprise messaging platform with a rich API and app ecosystem that integrates seamlessly with Ansible, ServiceNow, and monitoring tools. In AIOps workflows, Slack channels serve as a real-time hub where AI-driven alerts, diagnostics, and remediation updates are delivered directly to operations teams.
4. Build Ansible Lightspeed Job Template
The final piece of this workflow is creating (or updating) a Ansible Automation Platform job template with the insights we just gained from Red Hat AI.
We have a problem, such as an application outage, and we now have a solution: for example: “there is a mis-configuration on this line” and now we can use this information we gleaned and now prompt Ansible Lightspeed in the next workflow, the Remediation workflow. We are basically using one AI endpoint (Red Hat AI) to help create a prompt to a second AI endpoint (Ansible Lightspeed) to create an Ansible Playbook to help remediate the issue.
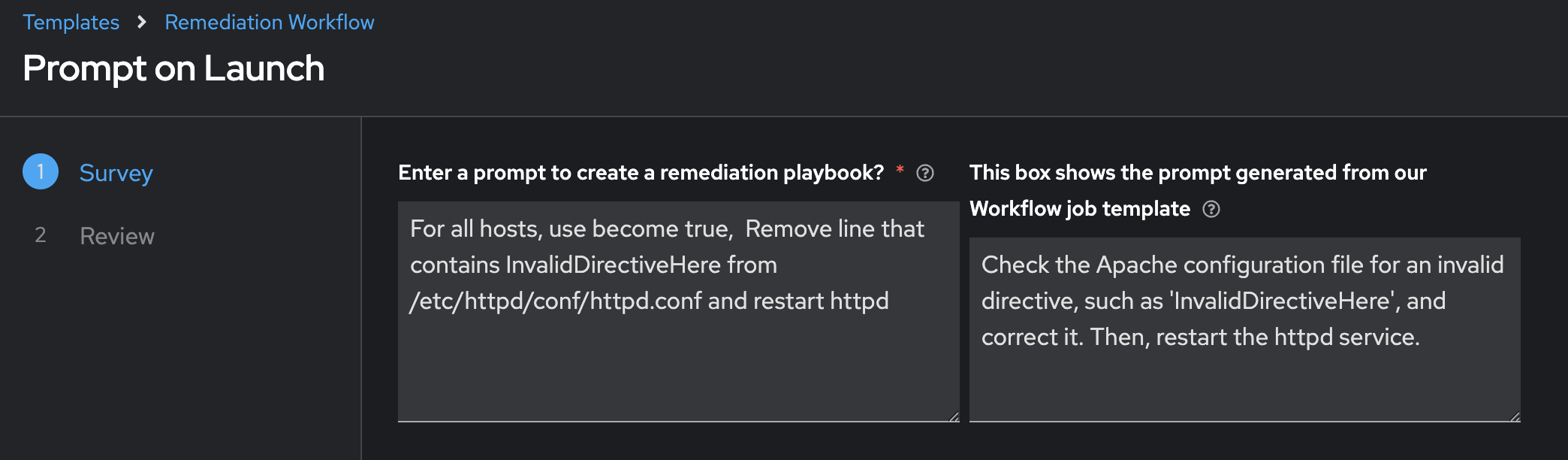
A way to do this (an opinionated way, but not the only way) is to use an Ansible Survey.
In the above screenshot, the left is the prompt we will use in the next workflow, while the right is the insights we gleaned from Red Hat AI based on all the information it had. This is a natural breakpoint where the human can course correct the prompt. We will still have time to review the solution before we move it into production, but it may make sense for your IT operations team to review this prompt before we move onto Lightspeed.
Could we make this one workflow?
YES! Absolutely. This is just showing how it is easy to adopt AIOps incrementally and add natural breakpoints to review what is happening as you adopt AI into your IT workflows.
Here is an excerpt from the Ansible Playbook used in our AIOps workshop:
- name: Create Job Template
ansible.controller.job_template:
name: "<img src="https://cdn.jsdelivr.net/gh/twitter/twemoji@14.0.2/assets/72x72/1f9e0.png" width="20" style="vertical-align:text-bottom;"> Lightspeed Remediation Playbook Generator"
job_type: "run"
inventory: "{{ input_inventory | default('Demo Inventory') }}"
project: "{{ input_project | default('AI-EDA') }}"
playbook: "{{ input_playbook | default('playbooks/lightspeed_generate.yml') }}"
credentials:
- "{{ input_credential | default('AAP') }}"
- "{{ vault_credential | default('ansible-vault') }}"
validate_certs: true
execution_environment: "Default execution environment"
- name: Load remediation workflow template
ansible.controller.workflow_job_template:
name: Remediation Workflow
organization: Default
state: present
survey_enabled: true
survey_spec: "{{ lookup('template', playbook_dir + '/templates/survey.j2') }}"
We are able to dynamically update the survey inside the workflow by using the survey_spec. The survey spec looks like the following:
{
"name": "Prompt Lightspeed",
"description": "Survey for working with Ansible Lightspeed",
"spec": [
{
"type": "textarea",
"question_name": "Enter a prompt to create a remediation playbook?",
"question_description": "This prompt will be used with Ansible Lightspeed to automatically generate an Ansible Playbook",
"variable": "lightspeed_prompt",
"required": true,
"default": "For all hosts, use become true, Remove line that contains InvalidDirectiveHere from /etc/httpd/conf/httpd.conf and restart httpd"
},
{
"type": "textarea",
"question_name": "This box shows the prompt generated from our Workflow job template",
"question_description": "This area shows you that AI was able to understand the error and create a prompt for Ansible Lightspeed.",
"variable": "ai_lightspeed_prompt",
"required": false,
"default": "{{ gpt_generated_prompt }}"
}
]
}
Now everytime the first workflow Log Enrichment and Prompt Generation Workflow runs, the second workflow Remediation Workflow automatically has its survey updates to be relevant to that workflow. This is doing Config as Code using the ansible.controller content collection.
Please consider using the AAP Configuration Collection on Automation hub. This content collection simplifies interactions for Ansible Automation Platform.
3. Remediation Workflow
The third part of the AIOps workflow is the Remediation Workflow. This workflow will take a prompt from the previous workflow, allow the human operator to customize this prompt, then build an Ansible Playbook to remediate the issue, sync this to git and build a job template that will run this playbook for the final step.
Here is a breakdown of the four main components:
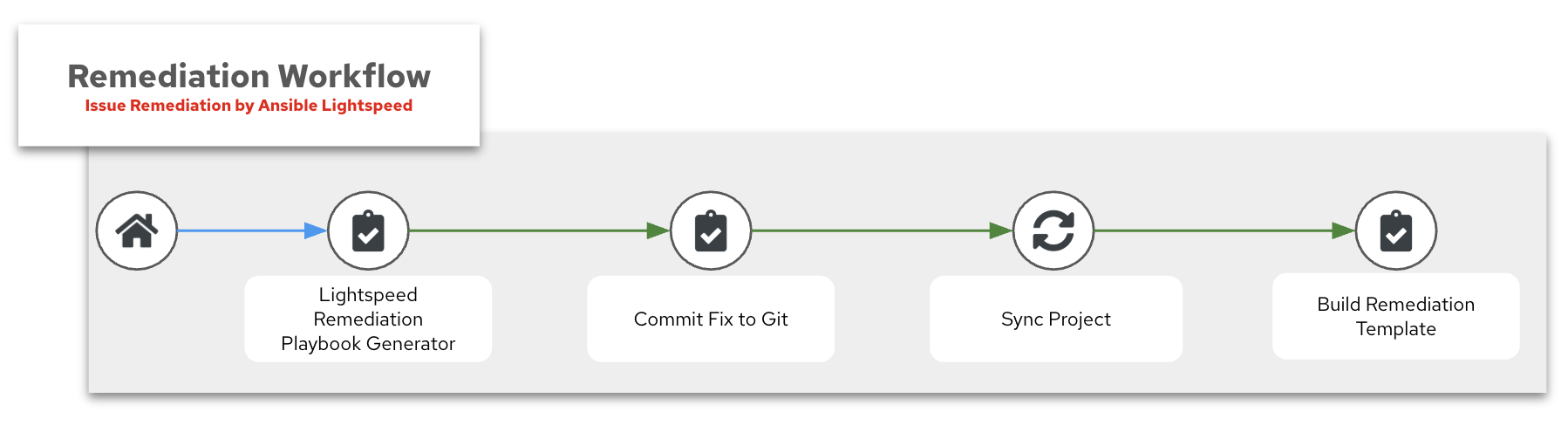
- Lightspeed Remediation Playbook Generator
- Commit Fix to Git
- Sync Project
- Build Remediation Template
1. Lightspeed Remediation Playbook Generator
Ansible Lightspeed also has an API. We can communicate to this API similarly as we do with Red Hat AI solutions. Here is an example task:
- name: Send request to AI API
ansible.builtin.uri:
url: "{{ input_lightspeed_url | default('https://c.ai.ansible.redhat.com/api/v0/ai/generations/') }}"
method: POST
headers:
Content-Type: "application/json"
Authorization: "Bearer {{ lightspeed_wca_token }}"
body_format: json
body:
text: "{{ lightspeed_prompt }}"
register: response
The API will respond with the Ansible Playbook as part of the payload under the playbook keyword. You can see the response in the Job Output window:
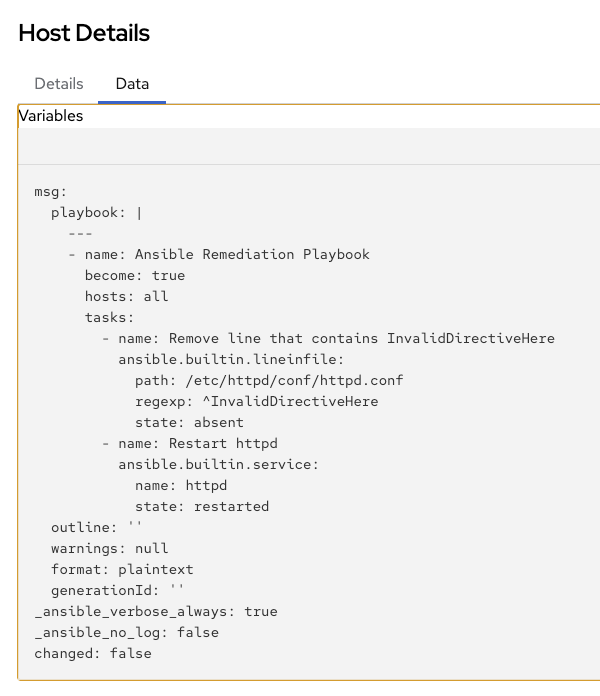
2. Commit Fix to Git
Once the Ansible Playbook is retrieved from Ansible Lightspeed, we need to store it in a Git repo. We can use the Ansible SCM (source control management) content collection to easily publish the content to any specified repo.
Here is an excerpt from our AIOps Workshop:
- name: Commit and push final version of playbook to Gitea
ansible.scm.git_publish:
path: "{{ repository['path'] }}"
token: "{{ gitea_token }}"
3. Sync Project
This is a special node type inside the Workflow Visualizer that will sync a Project. Since we just pushed this Ansible Playbook to Git we need to sync the Project to update and retrieve this playbook to be used in an Ansible Job Template. Here is a screen shot from the Workflow visualizer showing the Project Sync:
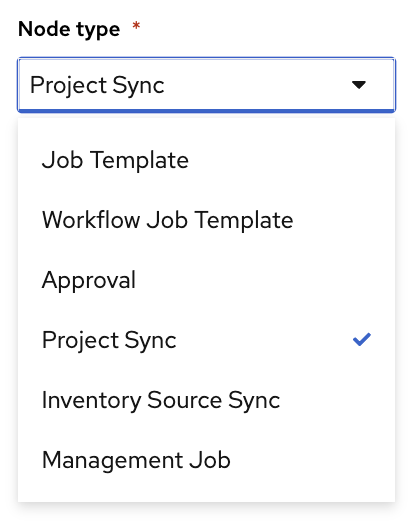
4. Build Remediation Template
The final job template inside this workflow is creating a new job template with the newly created Ansible Playbook. We can use the ansible.controller content collection to dynamically build this. Here is an example:
- name: Create Job Template
ansible.controller.job_template:
name: "<img src="https://cdn.jsdelivr.net/gh/twitter/twemoji@14.0.2/assets/72x72/1f527.png" width="20" style="vertical-align:text-bottom;"><img src="https://cdn.jsdelivr.net/gh/twitter/twemoji@14.0.2/assets/72x72/2705.png" width="20" style="vertical-align:text-bottom;"> Execute HTTPD Remediation"
job_type: "run"
inventory: "{{ input_inventory | default('lab-inventory') }}"
project: "{{ input_project | default('Lightspeed-Playbooks') }}"
playbook: "{{ input_playbook | default('lightspeed-response.yml') }}"
credential: "{{ input_credential | default('lab-credential') }}"
validate_certs: true
execution_environment: "Default execution environment"
become_enabled: true
ask_limit_on_launch: true
Could we just run the playbook now?
YES, but you may want to run the playbook during a specific change window. This is another natural breakpoint where you can add more guard rails before you push an Ansible job into production. Now that you have the Job Template queued up, you can run it whenever you want.
4. Execute Remediation
The final step is running the remediation Job Template that was dynamically created in the previous workflow. This is the Ansible Playbook that Lightspeed generated – committed to Git, synced to a project, and loaded into a Job Template – now ready to execute against the affected host.
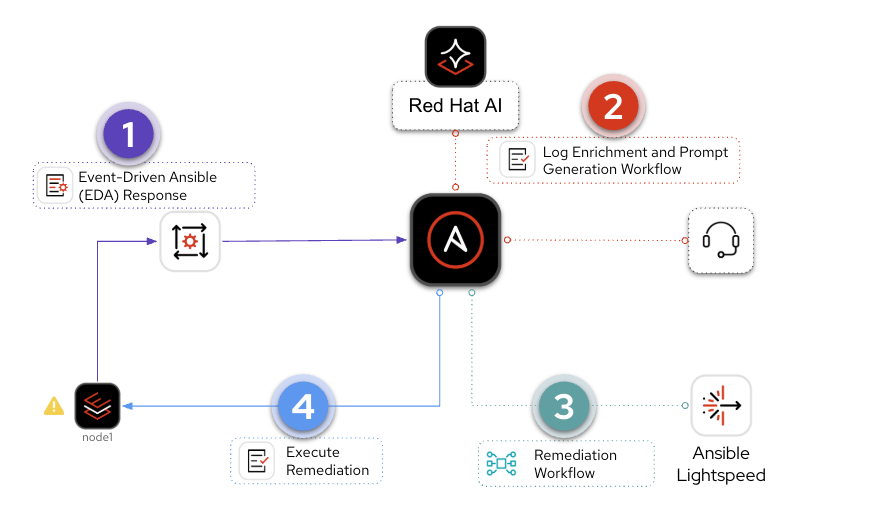
In the workflow diagram above, this is the Execute HTTPD Remediation node at the bottom – the final step before the system returns to steady state. Notice this is marked as a Manual Step. This is intentional: the human operator reviews the AI-generated playbook and decides when to execute, giving organizations a natural approval gate before changes reach production.
Why not fully automate this last step?
You absolutely can. For organizations further along their AIOps maturity, this final step can be wired directly into the Remediation Workflow so the fix executes automatically. The manual breakpoint exists for teams that want to adopt AIOps incrementally – gaining confidence in the AI-generated playbooks before removing the human gate.
Policy Enforcement
Before executing AI-generated playbooks in production, organizations should consider adding policy guardrails. Ansible Automated Policy as Code enables teams to define and enforce rules about what automation is allowed to do – for example, restricting which hosts can be targeted, which modules are permitted, or requiring approval workflows before high-impact changes.
In an AIOps context, policy enforcement is the safety net that lets you increase automation confidence over time:
| Maturity | Policy Approach |
|---|---|
| Crawl | Human reviews every AI-generated playbook before execution |
| Walk | Policy engine validates playbook content automatically; human approves execution |
| Run | Policy engine validates and auto-approves within defined boundaries; exceptions escalate to human |
Validation
Because this guide covers a reference architecture rather than a single tool integration, validation is done per workflow stage rather than with a single test command. Each stage has a clear success indicator that confirms the pipeline is working before moving to the next.
| Stage | What to Verify | Success Indicator |
|---|---|---|
| 1. EDA Response | Rulebook activation is running and receiving events | AAP shows the rulebook activation as Running; event log shows received events |
| 2. Enrichment Workflow | AI analyzed the incident and notifications were sent | Workflow Visualizer shows all nodes green; chat/ITSM received the AI-generated diagnosis |
| 3. Remediation Workflow | Lightspeed generated a playbook and it was committed to Git | New playbook file exists in the Git repository; Job Template was created with the correct playbook |
| 4. Execute Remediation | The AI-generated playbook resolved the issue | Job Template run completes successfully; the application or service returns to steady state |
Want hands-on validation?
The companion workshop Hands-On AIOps: Building Self-Healing, Observability-Driven Automation with Ansible walks through this entire pipeline end-to-end with a live lab environment. Part 1 covers Apache service remediation, Part 2 extends the same pattern to network automation with Splunk and Cisco routers.
Troubleshooting Across Workflow Boundaries
Most failures in an AIOps pipeline happen at the integration boundaries – where one stage hands off to the next. Here are the most common issues:
| Symptom | Boundary | Likely Cause | Fix |
|---|---|---|---|
| EDA rulebook is active but workflow never launches | EDA → Enrichment Workflow | Event payload doesn’t match rulebook condition | Compare the actual event JSON against the rulebook condition field |
| Enrichment Workflow runs but AI response is empty or generic | Enrichment → Red Hat AI | Prompt is missing context (no logs, no system info) | Verify the “Capture Additional Information” job collected data and passed it to the AI prompt |
| Lightspeed returns a playbook but it doesn’t fix the issue | Remediation → Execute | Prompt to Lightspeed was too vague or AI diagnosis was incorrect | Review the prompt in the Remediation Workflow survey; refine the AI-generated prompt before Lightspeed generates the playbook |
| Job Template was created but playbook is missing | Remediation → Git/Project Sync | Git commit failed or project sync didn’t run | Check Gitea/GitHub for the commit; verify the Project Sync node succeeded in the Workflow Visualizer |
AIOps Maturity Path
The Broader AIOps Journey
AIOps is not a single use case – it is a maturity journey. Organizations typically progress through increasing levels of complexity, starting with read-only enrichment and advancing toward autonomous, self-healing systems. Each stage builds on the previous one.
| Maturity | Use Cases | What AI Does |
|---|---|---|
| Incident & Ticket Enrichment, Cost & Resource Optimization | AI interprets operational signals and attaches context – no changes to systems | |
| Curated Automation Remediation, Intelligent Capacity Orchestration | AI selects from pre-approved automation – proven playbooks, governed execution | |
| Self-Healing Infrastructure, System-Level Drift & Policy Enforcement | AI generates or adapts remediation automation on-the-fly – constrained by policy guardrails |
AIOps is the outcome. Agentic is a capability.
Agentic workflows – where AI plans, uses tools, reflects on results, and iterates – can enhance any stage of this journey. But AIOps does not require agentic capabilities to deliver value. A deterministic EDA rulebook that enriches a ServiceNow ticket is AIOps at the Crawl stage. A fully autonomous agent that reasons about OSPF failures is AIOps at the Run stage. Start where you are.
Self-Healing Infrastructure: Crawl, Walk, Run
This guide covers the self-healing infrastructure use case, which has its own maturity progression. The key difference at each stage is how much autonomy AI has over the remediation:
| Maturity | Approach | How It Works | AI Role |
|---|---|---|---|
| Ticket Enrichment | EDA detects event → AI diagnoses root cause → enriched context is posted to chat/ITSM → human remediates manually | Read-only: AI interprets, humans act | |
| Curated Remediation | EDA detects event → AI diagnoses root cause → AI selects the right playbook from a pre-approved library → human approves → playbook executes | AI selects from existing automation; no new code is created | |
| Self-Healing | EDA detects event → AI diagnoses root cause → Ansible Lightspeed generates a new remediation playbook → policy engine validates → playbook executes | AI generates new automation on-the-fly within policy boundaries |
The workflow in this guide demonstrates the Run stage – AI generates a remediation playbook that didn’t exist before. But organizations can start at Crawl by using only the Enrichment Workflow (parts 1-2) and stopping before the Remediation Workflow. Each stage reuses the same underlying architecture; the difference is how far down the pipeline you automate.
Where Do Good Playbooks Come From?
The AIOps pipeline in this guide uses Automation code assistant to generate remediation playbooks on-the-fly. But AI-generated code is not the only source of production-quality automation. Organizations should draw from multiple playbook sources depending on the use case:
| Source | Description |
|---|---|
| CVE Remediation (Red Hat Lightspeed) | Red Hat Lightspeed (formerly Red Hat Insights) identifies vulnerabilities affecting your RHEL fleet and generates targeted playbooks to patch them. These are based on Red Hat’s Security Data API and errata – not AI-generated, but battle-tested remediation from Red Hat Support. |
| Advisor Recommendations (Red Hat Lightspeed) | Lightspeed flags misconfigurations and best-practice violations (e.g., SELinux policy issues, SSH configurations that won’t survive a reboot) and generates playbooks to fix them proactively. Think of CVEs as reactive – patching known vulnerabilities. Advisor recommendations are proactive – fixing misconfigurations before they become incidents. |
| RHEL System Roles | Officially supported, pre-built Ansible roles shipped with RHEL that provide a stable, version-independent interface for common configuration tasks (NTP, networking, storage, SELinux, firewall). A playbook using works the same on RHEL 8 and RHEL 9. |
| AI-assisted authoring (Automation code assistant) | Developers use Automation code assistant in the IDE to accelerate playbook creation. The AI generates a first draft from natural language, then a human reviews, refines, and validates before committing. Supports Google Gemini, Red Hat AI, and IBM watsonx as backends. |
Human-in-the-loop is what makes it production-ready.
Whether a playbook was generated by Red Hat Lightspeed, written with AI assistance, or hand-crafted, the same review and approval process applies: Git as source of truth, project sync in AAP, Job Templates with guardrails (credentials, inventory limits, surveys), and optional approval gates. The IDE is where the review happens; AAP is where the gatekeeping happens.
Each source has its place in the AIOps maturity journey. At the Crawl stage, Red Hat Lightspeed CVE and Advisor playbooks give you ready-made, trusted content. At Walk, curated RHEL System Roles and pre-approved playbook libraries provide governed automation. At Run, Automation code assistant generates new playbooks on-the-fly within policy boundaries.
Related Guides
- Need to deploy the AI backend? See AI Infrastructure automation with Ansible for automating Red Hat AI provisioning with the
infra.aiandredhat.aicollections.  Want to try this hands-on? The Hands-On AIOps Workshop walks through the full self-healing pipeline with a live lab – Part 1 covers Apache remediation, Part 2 extends to network automation with Splunk and Cisco routers.
Want to try this hands-on? The Hands-On AIOps Workshop walks through the full self-healing pipeline with a live lab – Part 1 covers Apache remediation, Part 2 extends to network automation with Splunk and Cisco routers.- New to Event-Driven Ansible? See Get started with EDA (Ansible Rulebook) for the fundamentals of rulebooks, event sources, and actions.
 Looking for ticket enrichment? See ServiceNow ITSM Ticket Enrichment Automation – a great starting point for the Crawl stage of AIOps.
Looking for ticket enrichment? See ServiceNow ITSM Ticket Enrichment Automation – a great starting point for the Crawl stage of AIOps.
Summary
With this workflow in place, your team moves from manually triaging every alert to AI-diagnosed, dynamically remediated incidents. Instead of writing hundreds of rules to match hundreds of failure modes, a single AIOps pipeline uses AI inference to diagnose issues and Automation code assistant to generate remediation playbooks on-the-fly. Combined with pre-built remediation from Red Hat Lightspeed (CVE and Advisor playbooks) and RHEL System Roles, organizations have multiple sources of trusted automation at every stage of the maturity journey. The result is faster mean time to resolution (MTTR), less operational toil, and an automation strategy that scales with your environment rather than against it.
Next Steps
| Try Ansible Automation Platform | Start a free 60-day trial and build your first automation workflows |
| Red Hat Consulting | Work with Red Hat experts to design, implement, and scale AIOps automation tailored to your environment |
| Training and Certification | Build team skills with hands-on courses and industry-recognized certifications |
![]()